
https://www.washingtonpost.com/technology/2021/10/25/facebook-papers-live-updates/
No artigo anterior, expus sobre como o capitalismo se reinventou na internet que, supostamente, nos libertaria dele, em algo chamado de “Capitalismo de Vigilância”, cuja principal fonte de lucro das mega corporações seriam os dados que produzimos.
Entretanto, como essas corporações conseguem maximizar essa coleta de dados e como ela consegue tanto dinheiro com eles? Afinal, não pode ser a toa termos elas na lista de empresas mais valiosas do mundo. E será que toda a polarização política no Brasil, e no mundo, é só uma coincidência? Será que a descrença nas instituições públicas e científicas teria alguma coisa a ver? Será que há pessoas lucrando em cima disso?
Neste artigo irei analisar essas questões, explorando as consequências da maximização de lucros feitas pelas Big Techs ao minerar, de forma descontrolada, nossos dados. Se prepare que hoje o artigo é longo :)
Como as Máquinas Aprendem?

O ponto central para entender o nível de distopia em que chegamos na nossa sociedade, com teorias da conspiração malucas se tornando populares e a nova escalada do autoritarismo, é compreender o conceito de Machine Learning, ou, aprendizado de máquina. E isso é fundamental para escaparmos da alienação que essas empresas querem que seus usuários tenham, como expliquei no artigo passado.
Então, vamos entrar um pouco numa parte mais técnica. Prometo que tentarei ser o menos específico possível!
Você já parou para pensar o que é aprender? Tente lembrar de quando você era muito pequeno. Como você começava a entender as coisas? Como você aprendeu a falar, a ler e a escrever? Por que quando você vê um carro, você, na hora, já reconhece que este é um carro?
Basicamente, você, ao longo de sua aprendizagem, coletou dados, sejam visuais ou sonoros por exemplo, a passou a criar padrões. Na primeira vez que você viu um carro, você provavelmente não se lembra, mas certamente não sabia o que era. Depois de obter experiência, observando, ouvindo e entrando em carros, você entendeu que, se um objeto possui um certo tamanho, quatro rodas, portas, vidros, faz um certo barulho, anda, etc…, este, ao menos provavelmente, é um carro. E agora, eu tenho certeza que você consegue identificar um carro instantaneamente, com pouca chance de erro. Seria bem improvável que você, ao ver uma moto, a confundisse com um carro…
Os computadores aprendem de forma bem parecida: eles recebem dados e, através de algoritmos (existem diversos para isso), passam a criar espécies de “padrões”, e a identificar o que aprender, ou até realizar previsões, dependendo do tipo de algoritmo envolvido.
Quis explicar isso pois, devemos entender a diferença entre duas das classes de aprendizado de máquina: o aprendizado supervisionado e o não supervisionado.
No aprendizado supervisionado, o algoritmo irá utilizar dados que já foram classificados. É como se, quando você visse carros, seus pais ficassem te dizendo a cada momento que isso era um carro, ou não. Uma hora você passaria a identificar sozinho.
Já no aprendizado não supervisionado, o algoritmo irá classificar dados que ele não saberá, a priori, o que são. Este processo é chamado de “clustering”, e também existem diversos algoritmos para isso.
Parece algo de outro mundo imaginar um algoritmo classificando dados sem ter conhecimento do que eles são a priori. Mas não é. Pense que os dados seriam agrupados de acordo com a semelhança entre eles. Então, imagine que o software estaria analisando várias imagens de carros e motos, e ele precisa classificar o que é o que. No processo de clustering, ele separaria veículos que tivessem 4 rodas, um certo tamanho, mais de um lugar em um grupo. Em outro grupo, separaria os veículos com 2 rodas, de um outro tamanho médio,e com apenas um lugar.
Sistemas de Recomendação e Bolhas Sociais
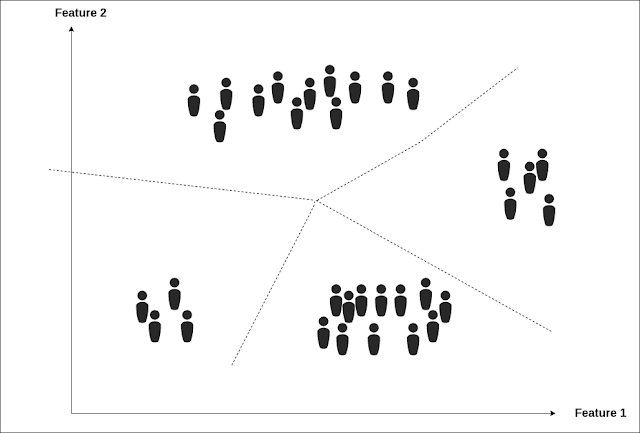
As redes sociais utilizam esse processo de aprendizado de máquina para recomendar conteúdos que mais agradam aos seus usuários. Dessa forma, ela consegue o manter mais “preso” e fiel a ela. Nesse caso, o aprendizado de máquina não supervisionado é crucial, pois dessa forma, o sistema consegue “aprender” sobre os gostos de cada usuário e assim ir recomendando conteúdos que correspondem tal gosto.
Agora, imagine a seguinte situação: Paulo é um esportista de tiro. Ele nunca foi de se envolver com política, só possui uma boa estabilidade financeira e gosta de passar seu tempo praticando e competindo. Com a popularização do Youtube e Facebook, ele resolveu passar a se conectar com outras pessoas do tiro esportivo e a consumir vídeos sobre o tema no Youtube.
Já Carlos, é uma pessoa bem politizada, de direita, que apoia muito Bolsonaro e sua família. Uma das causas que Carlos defende é a da liberação das armas e, apesar de não praticar tiro esportivo, ele também gosta de assistir a vídeos sobre o tema, assim como Paulo.
Logo, o algoritmo de aprendizado não supervisionado do youtube, que está presente em seu sistema de recomendação, tenderá a recomendar vídeos que pessoas como Carlos também assistem, de política de Direita, sobre liberação das armas, e, dependendo se Paulo aceitar as recomendações de início, mais vídeos ainda irão aparecer para ele.
Assim, esse tipo de sistema começa a influenciar pessoas de alguns seguimentos que não teriam a ver, ao menos não diretamente, com algum outro tema.
A partir daí, a cada dia que Paulo e Carlos abrem o Youtube e Facebook, mais conteúdos desse lado da política passam a aparecer, afinal, é o que o sistema entendem que eles gostam. Paulo então começa a consumir mais vídeos de política, enquanto Carlos passa cada vez mais a ser um radical, já que só recomendações deste lado e desta visão de mundo aparecem a ele.
Ambos acabam ficando tal como um cavalo com antolhos, sem conseguir enxergar para outros lados, já que, para eles, estes outros lados não existiriam ou estariam totalmente errados, tal como uma Terra Plana.
E este é exatamente o cenário em que o Brasil, e o mundo, se encontram devido às redes sociais: segregado em bolhas, onde só conseguem acessar o que condizem com suas opiniões e visões de mundo.
Um estudo do MIT, conduzido pelo professor Ethan Zuckerman, já concluia isso em 2017:
“Como o algoritmo do Facebook apresenta conteúdo ao usuário com base naquilo de que ele gostou e que escolheu no passado, sua tendência é reforçar ideias preconcebidas, tanto por ser provável que os amigos de uma pessoa concordem com seu ponto de vista quanto porque o comportamento on-line indica ao Facebook o conteúdo que mais lhe interessa.” — Ethan Zuckerman
E será que essas bolhas sociais são algo planejado pelas BigTechs ou foram apenas um erro, algo não planejado por elas, que acabou acontecendo, com um sistema de recomendação feito para agradar seus usuários, na melhor das intenções?
Facebook Papers: Eles Sabiam!
Ex-Engenheira do Facebook depõe ao senado dos EUA — Créditos: EPA

Em Setembro de 2021, a então Cientista de Dados do Facebook, Frances Haugen, vazou diversos documentos internos da empresa ao The Wall Street Journal, que publicou, com base neles, uma série de artigos intitulados: The Facebook Files, que ficaram conhecidos pela mídia também como “Facebook Papers”. Esses documentos revelam que, não só o que analisamos acima é verdade, como a empresa sabia disso, tinha condições de combater e escolheu não fazer nada. E por que? Lucro, lucro e mais lucro! Ganância! Prata!
Bolhas sociais geradas por conteúdo radicalizado viralizam muito mais do que qualquer coisa, e isso não é novidade para qualquer pessoa que use redes sociais. E quais seriam os maiores contribuidores para essa radicalização? Fake News! Sim, estas também geram MUITO lucro para as Big Techs. Segundo um estudo do MIT, fake news possuem 70% mais chances de se espalharem que notícias reais. Se as redes sociais ganham justamente com o acesso ao conteúdo, imagine se elas iriam abrir mão de tudo isso…
Como bem aponta a jornalista Tatiana Dias, do Intercept: Google, Twitter e Facebook lucram quando você sente raiva!
E tudo isso agora é comprovado com o Facebook Papers. O Facebook sabia muito bem que a desinformação e discurso de ódio gerariam mais engajamento:
“Os documentos mostram que pesquisas internas revelaram que ofensas e desinformação são mais passíveis de viralizar. Estudos de feedback e experiência de usuário também deixaram claro que a mudança no algoritmo fazia com que usuários e atores políticos passaram [sic] a postar mais conteúdos divisivos e sensacionalistas para conseguirem mais interação e distribuição.” —Tatiana Dias, Intercept Brasil
E não só isso: diversos funcionários da empresa haviam proposto mudanças, que, segundo pesquisas, diminuiriam consideravelmente a propagação desse tipo de conteúdo. Resultado? Negado por Zuckerberg.
E lembra do cenário do Paulo e Carlos que inventei para ilustrar como ocorre o surgimento das bolhas sociais? Então, de acordo com um estudo do próprio Facebook, vazado em um dos documentos, Paulo precisaria de apenas 4 semanas para se tornar um radical.
Neste estudo, intitulado “Carol’s Journey to QAnon — A Test User Study of Misinfo & Polarization Risks Encountered through Recommendation Systems”, pesquisadores da empresa criaram contas fake para analisar como o algoritmo da rede social poderia espalhar desinformação. Essas contas começaram a seguir páginas Mainstream conservadoras, como Fox News, Donald Trump e , a então primeira dama, Melania Trump. Em apenas 2 dias já apareceram recomendações de grupos conspiracionistas como QAnon.
Por fim, depois de 3 estudos, a conclusão foi que um usuário demoraria apenas 4 semanas para se tornar um radical.
Democracia em Cheque

Invasão do Capitólio em Janeiro de 2021 —(Tyler Merbler/WikiMedia)
Aquela internet utópica dos anos 90, que iria nos dar liberdade de expressão, autonomia para escapar do sistema e afins, acabou nos levando em uma verdadeira distopia da pós verdade.
Vimos que esse uso desenfreado da exploração de dados e do uso de sistemas de recomendação sem qualquer controle possuem fins gananciosos de maximização de lucros, e faz com que nos deparemos com o cenário da imagem acima: milhares de pessoas tentando dar um golpe de Estado e derrubar o maior símbolo do Estado Democrático de Direito.
Mostrei principalmente o caso do Facebook, já que é a rede social mais usada do mundo (incluindo Instagram), mas não se engane: outras empresas como Google (Youtube principalmente) e Twitter, por exemplo, também lucram com isso.
Enfim, o sistema sempre se remodela e se sobrepõe sobre o povo, cabe a nós resistirmos (falarei mais sobre isso nos próximos artigos).
Ao menos agora, sabemos que os culpados tem nome e endereço…